Abstract
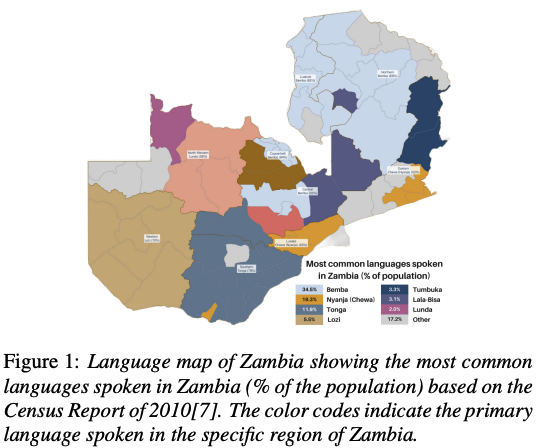
his work introduces Zambezi Voice, an open-source multilingual speech resource for Zambian languages. It contains two collections of datasets: unlabelled audio recordings of radio news and talk shows programs (160 hours) and labelled data (over 80 hours) consisting of read speech recorded from text sourced from publicly available literature books. The dataset is created for speech recognition but can be extended to multilingual speech processing research for both supervised and unsupervised learning approaches. To our knowledge, this is the first multilingual speech dataset created for Zambian languages. We exploit pretraining and cross-lingual transfer learning by finetuning the Wav2Vec2.0 large-scale multilingual pre-trained model to build end-to-end (E2E) speech recognition models for our baseline models. The dataset is released publicly under a Creative Commons BY-NC-ND 4.0 license and can be accessed via https://github.com/unza-speech-lab/zambezi-voice.
Antonios Anastasopoulos
Assistant Professor
I work on multilingual models, machine translation, speech recognition, and NLP for under-served languages.