Approaches to Corpus Creation for Low-Resource Language Technology: the Case of Southern Kurdish and Laki
Abstract
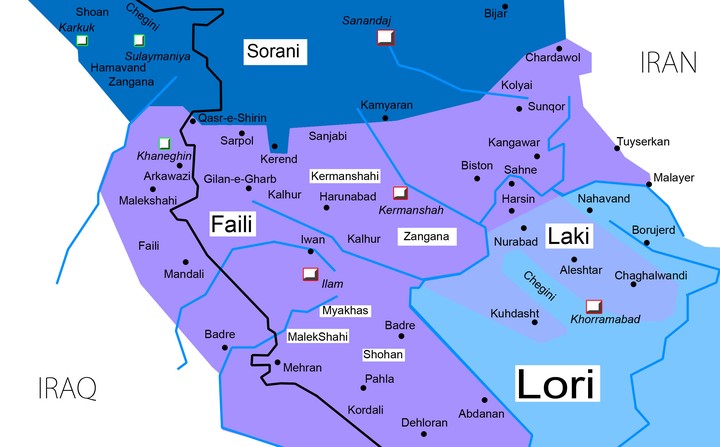
One of the major challenges that under-represented and endangered language communities face in language technology is the lack or paucity of language data. This is also the case of the Southern varieties of the Kurdish and Laki languages for which very limited resources are available with insubstantial progress in tools. To tackle this, we provide a few approaches that rely on the content of local news websites, a local radio station that broadcasts content in Southern Kurdish and fieldwork for Laki. In this paper, we describe some of the challenges of such under-represented languages, particularly in writing and standardization, and also, in retrieving sources of data and retro-digitizing handwritten content to create a corpus for Southern Kurdish and Laki. In addition, we study the task of language identification in light of the other variants of Kurdish and Zaza-Gorani languages.
Sina Ahmadi
Postdoctoral Researcher
Antonios Anastasopoulos
Assistant Professor
I work on multilingual models, machine translation, speech recognition, and NLP for under-served languages.