Investigating Post-pretraining Representation Alignment for Cross-Lingual Question Answering
Abstract
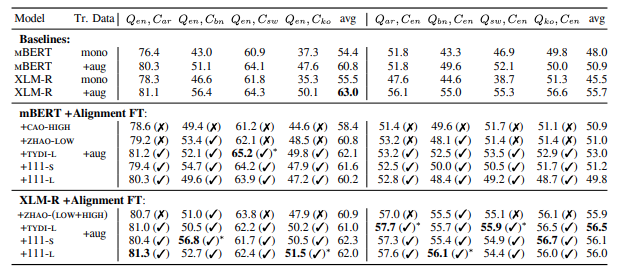
Human knowledge is collectively encoded in the roughly 6500 languages spoken around the world, but it is not distributed equally across languages. Hence, for information-seeking question answering (QA) systems to adequately serve speakers of all languages, they need to operate cross-lingually. In this work we investigate the capabilities of multilingually pre-trained language models on cross-lingual QA. We find that explicitly aligning the representations across languages with a post-hoc fine-tuning step generally leads to improved performance. We additionally investigate the effect of data size as well as the language choice in this fine-tuning step, also releasing a dataset for evaluating cross-lingual QA systems.
Fahim Faisal
PhD Student
My name is Fahim Faisal. My academic interest involves learning different aspects of computational linguistics and natural language processing (eg. machine translation). Currently, I am working on a project related to semi-supervised learning of morphological process of language.
Antonios Anastasopoulos
Assistant Professor
I work on multilingual models, machine translation, speech recognition, and NLP for under-served languages.